As Siri virtual assistant stands to gain hordes of new users around the world with the iPhone 5s and 5c, Apple is looking to improve accurate voice recognition through geolocation and localized language models.
Apple's iOS devices already boast a number of voice-recognizing input features, including Siri and speech-to-text, but worldwide availability makes accurate representation of some local dialects and languages an issue.
Looking to improve the situation, Apple is investigating ways to integrate location data with language modeling to create a hybrid system that can better understand a variety of tongues. The method is outlined in a patent filing published by the U.S. Patent and Trademark Office on Thursday, titled "Automatic input signal recognition using location based language modeling."
Apple proposes that a number of local language models can be constructed for a desired service area. A form of such a system is already in use with Siri's language selection, which allows users to choose from various models, like English (United States) and English (United Kingdom).
However, the method can serve the opposite effect and further complicate system recognition. Apple explains:
That is, input signals that are not unique to a particular region may be improperly recognized as a local word sequence because the language model weights local word sequences more heavily. Additionally, such a solution only considers one geographic region, which can still produce inaccurate results if the location is close to the border of the geographic region and the input signal corresponds to a word sequence that is unique in the neighboring geographic region.
Apple's new invention hybridizes local language models by weighting them according to location and speech input, then merging them with other localized or global models. Global models capture general language properties and high-probability word strings commonly used by native speakers.
In some embodiments, the local language model is first identified by geography, which is governed by service location thresholds. This first model is merged with the global version of the language and compared against input words or phrases that are statistically more likely to occur in the specified region.
Information data can be used to pick out word sequences that have a low likelihood of occurrence globally, but may be higher for a certain location. The document offers the words "goat hill" as an example. The input may have a low probability of being spoken globally, in which case the system may determine the speaker is saying "good will." However, if geolocation is integrated, it may be recognized that a nearby store is called Goat Hill, leading the system to determine that input as the more likely word string.
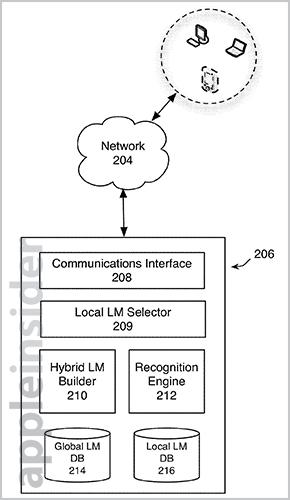
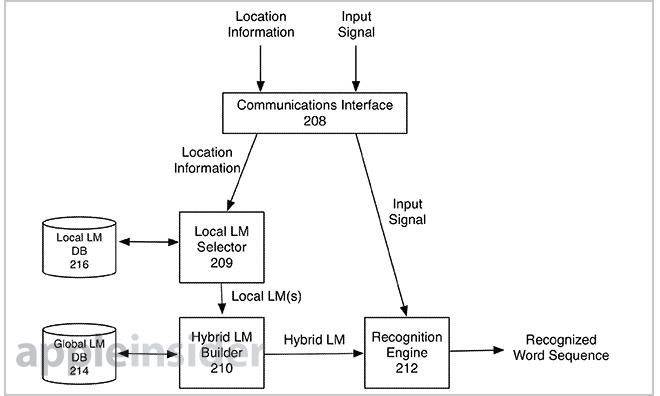
Location data can be gathered via GPS, cell tower triangulation, and other similar methods. Alternatively, a user can manually enter the location into a supported device. Language assets include databases, recognition modules, local language model selector, hybrid language model builder, and a recognition engine.
Combining the location data with local language models involves a "centroid," or a predefined focal point for a given region. Examples of the so-called centroid can be an address, building, town hall, or even the geographic center of a city. When the thresholds surrounding centroids overlap, "tiebreaker policies" can be implemented to weight one local language model higher than another, creating the hybrid language model.
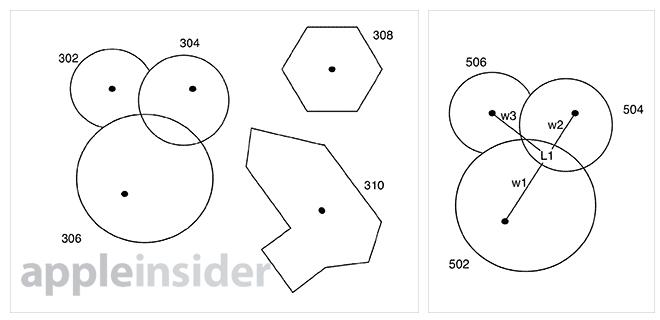
Illustration of overlapping regions and centroids.
While it is unknown if Apple will one day use the system in its iOS product line, current technology does allow for such a method to be implemented. Cellular data can be leveraged for database duties, while on-board sensors and processors would handle location gathering, language recognition and analysis, and hybrid model output.
Apple's location-based speech recognition patent application was first filed for in 2012 and credits Hong M. Chen as its inventor.