Audio-only group FaceTime calls with multiple people could be easier to deal with in the future, as Apple has suggested a way to process audio to implement the "cocktail party" effect, to make it easier to determine who is speaking.
Conference calls have made it easier to communicate ideas with many other people at the same time, and has become an essential tool for business. While handy, such calls can present their own problems, simply caused by having too many people taking part.
With multiple people in a call, it can be difficult to determine who is speaking at any one time. While video calls offer visual cues to identify the current speaker, audio-only calls do not have that luxury, leaving it up to the user to recognize the voice.
A patent application from Apple published by the U.S. Patent and Trademark Office on Thursday for "Intelligent augmented audio conference calling using headphones" suggests how the use of stereo headphones and software could be used to separate out the participants.
To solve the problem, Apple proposes splitting up each separate channel from individual callers in a multi-party call. These channels are then fed into a system to simulate a virtual audio environment or "room" with appropriate acoustic properties for the listener's local environment, to make the call seem more like it is taking place in the actual room.
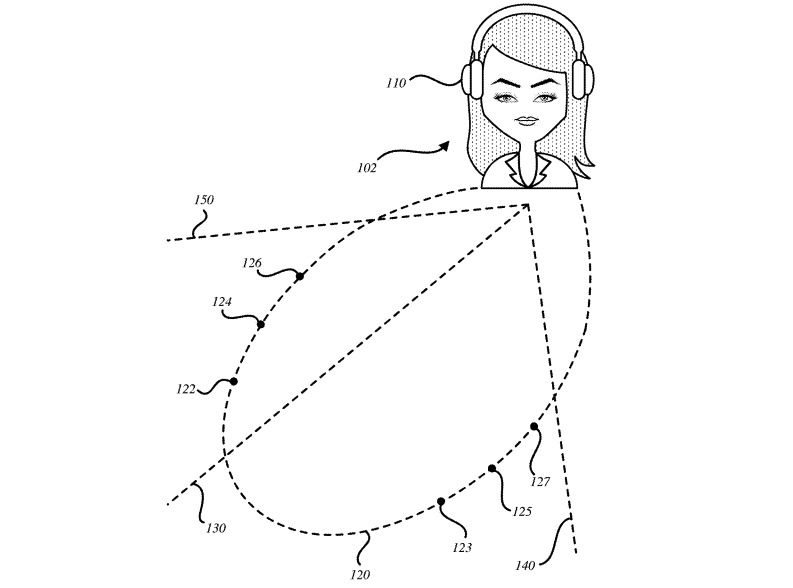
Apple patent application illustrating placement of multiple callers in a "virtual room" relative to the user
The remote callers are spaced apart in the virtual room, with the audio feeds for each participant adjusted so as to give the effect of the remote user's voice coming from different areas of the real room, such as around a conference table. Using a head-tracking system with the stereo headphones, the relative position of each remote user can be maintained while the user moves their head, with audio properties changing to match the user's orientation.
By using a spatial rendering audio system, Apple suggests it takes advantage of the "cocktail party mechanism" of the listener's brain for segregating audio sources. In short, placing voices in particular positions, it makes the conference call easier to track for the listener.
It is suggested the system could also use metadata to intelligently cluster together participants, such as co-workers or by company, frequency of speech, and geographic location, among other details. The virtual direction and distance of each caller could be further controlled by the user depending on their preferences, and there is even the possibility of "moving" participants around during the call, as in the case of one presenter switching out their position leading the call with another.
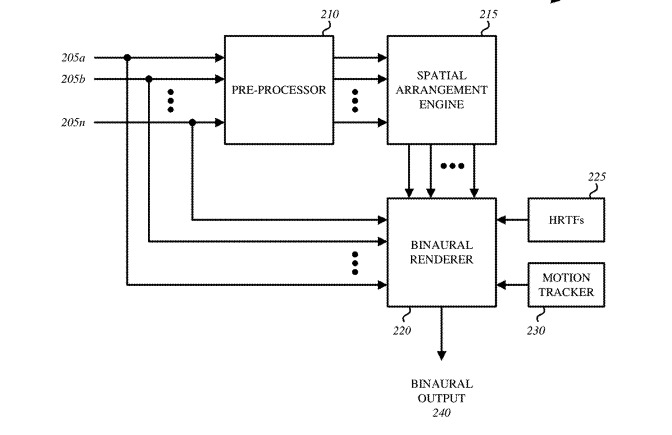
A block diagram showing how the audio feeds would be processed
Apple files a number of patent applications every week, and while the publication by the USPTO may indicate areas of interest to the company, it isn't a guarantee the described concepts will make their way into future consumer products.
In this case, there is a fairly good chance some form of the idea could work. The virtual "room" and audio alterations can certainly be performed on mobile devices and fed through stereo headphones, and while there aren't head-tracking headphones, it is feasible to work using other technologies, such as using an iPhone's FaceTime camera to detect changes in the direction the user is facing.
This is far from the only patent or application Apple has come up with relating to audio and headphones. In October and November, Apple suggested ways to detect how headphones are worn using capacitive proximity sensors and a microphone array.
There are also filings relating to "spatial headphone transparency" to make an audio feed seem like it is coming from a user's surroundings instead of headphones, a dual-mode headphone that could double as a speaker, and headwear that could be used for health monitoring.