
An app called Diffusion Bee lets users run the Stable Diffusion machine learning model locally on their Apple Silicon Mac to create AI-generated art. Here's how to get started.
Stable Diffusion is a text-to-speech machine learning model that can be used for generating digital artwork. As an example, typing something like "monkey riding a bicycle while wearing a top hat" will generate that image.
Using AI to create art has been popular in recent years as machine learning models are improved. Stable Diffusion is one such model, and others include DALL-E and Midjourney.
Diffusion Bee is billed as the easiest way to run Stable Diffusion locally on an M1 Mac. It's a one-click installer hosted on GitHub that runs Stable Diffusion locally on the computer.
Diffusion Bee app
No data is sent to a cloud other than the app's request to install weights for the model and software updates. No software dependencies are needed. The app is 561MB in size.
System Requirements
- M1 or M2 Mac
- 16GB of RAM for optimal performance. It may run slowly with 8GB RAM.
- macOS Monterey 12.5.1 or later.
To use Diffusion Bee, download and install the app. After installation, the app downloads two machine learning models. The first one is 4GB in size and the second is 341MB.
What you get with Diffusion Bee, and what to expect
Once the app is opened and the models are installed, there is a text field for art prompts. There is also an Image to Image category which the developers say is coming soon. Use that text field, for now.
Generating an image may take some time, depending on the size and the prompt. It took a couple force-quits of the app to finally start generating images.
The first text prompt at a size of 768 pixels from the drop down menu took so long to generate that we quit the app. After two attempts and force quits, images started working.
Under advanced options, there are menus for image height, width, steps, and guidance scale. Without delving deeply into documentation, we're not sure what the latter two mean, but we left everything at default.
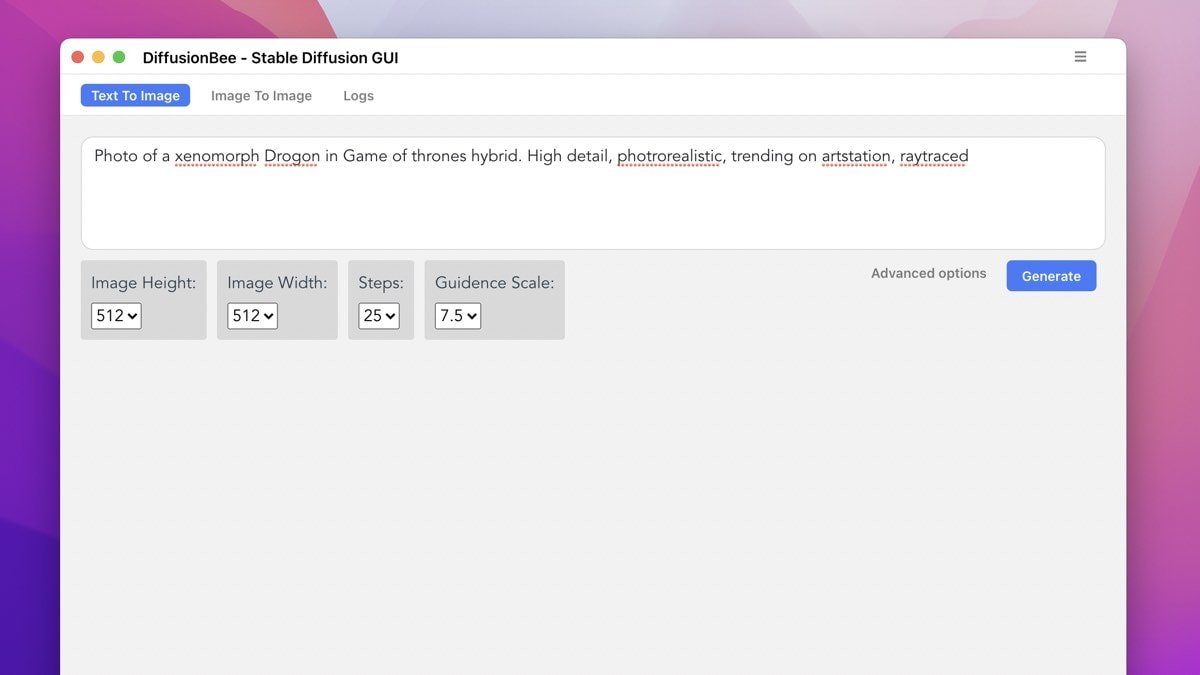
It's best to be descriptive in the text prompt; the example image that the developer shared used the prompt, "Photo of a xenomorph drogon in Game of Thrones hybrid, High detail, photorealistic, trending on artstation, raytraced."
We wanted to recreate an epic scene, so our prompt was, "demons chasing a black cat who is holding a scythe and riding a white horse. High detail, oil painting, photorealistic," and this is what the model spit out.

And I looked, and behold a pale horse: and his name that sat on him was Death Kitten, and Hell followed with him.
There are more examples at the ArtHub.ai website that hosts generated images along with their prompts, all which can be used for inspiration.







