
Apple on Thursday published a new entry to its Machine Learning Journal for researchers and developers, discussing face detection and the related Vision framework, which developers can use for apps on iOS, macOS, and tvOS.
Titled "An On-device Deep Neural Network for Face Detection," the paper covers the obstacles towards making Vision work, particularly maintaining privacy by running detection locally instead of through cloud servers.
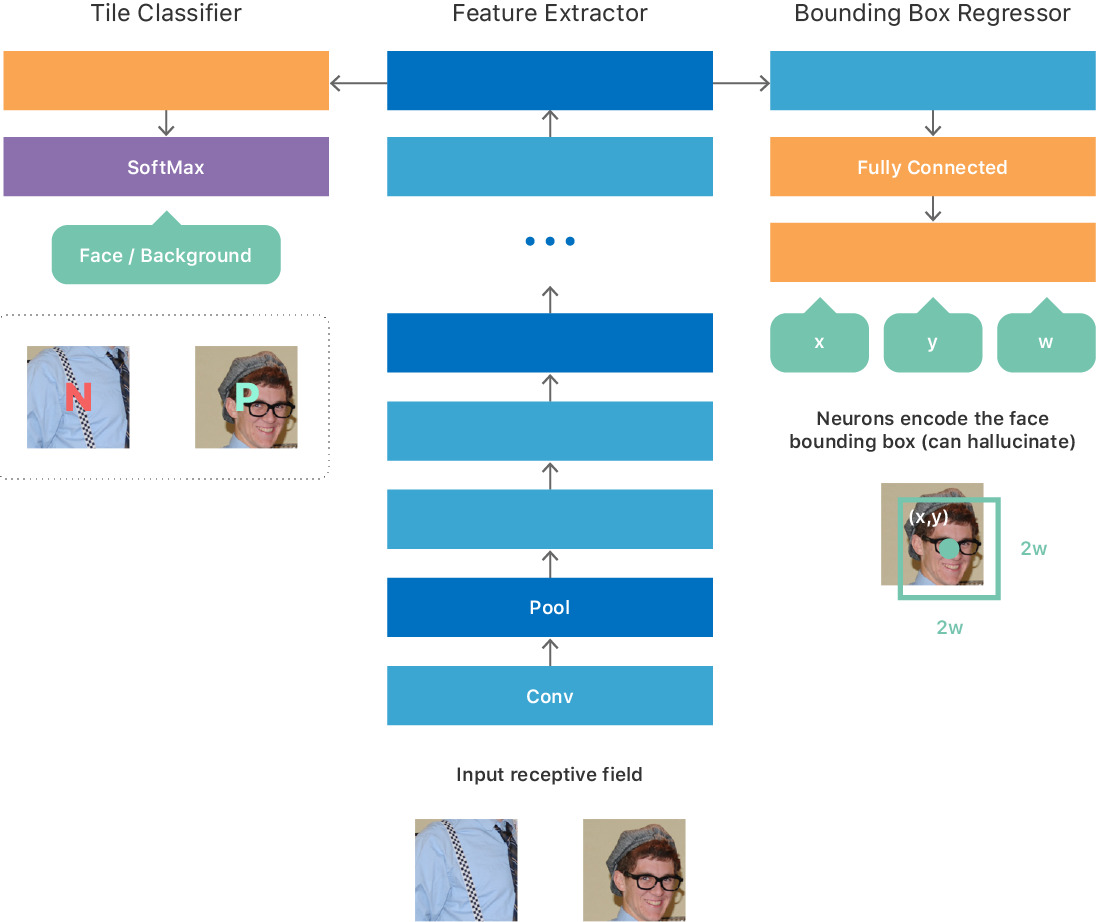
"The deep-learning models need to be shipped as part of the operating system, taking up valuable NAND storage space," Apple's Computer Vision Machine Learning Team writes. "They also need to be loaded into RAM and require significant computational time on the GPU and/or CPU. Unlike cloud-based services, whose resources can be dedicated solely to a vision problem, on-device computation must take place while sharing these system resources with other running applications. Finally, the computation must be efficient enough to process a large Photos library in a reasonably short amount of time, but without significant power usage or thermal increase."
To solve these issues, the framework was optimized to "fully leverage" CPUs and GPUs, using Apple's Metal graphics and BNNS (basic neural network subroutines), a group of functions for running neural networks with existing training data. Memory use was optimized for network inference, and image loading and caching.
Apple has been investing deeply in machine learning, even implementing a dedicated "Neural Engine" for the A11 Bionic processor in the iPhone 8 and X. Earlier this year, CEO Tim Cook said that machine learning is at the heart of Apple's self-driving car platform, currently in testing on California roads.







