Apple on Wednesday published another paper through its Machine Learning Journal, this time covering the topic of differential privacy — the technology it employs to collect big data from customers while obscuring their identities.
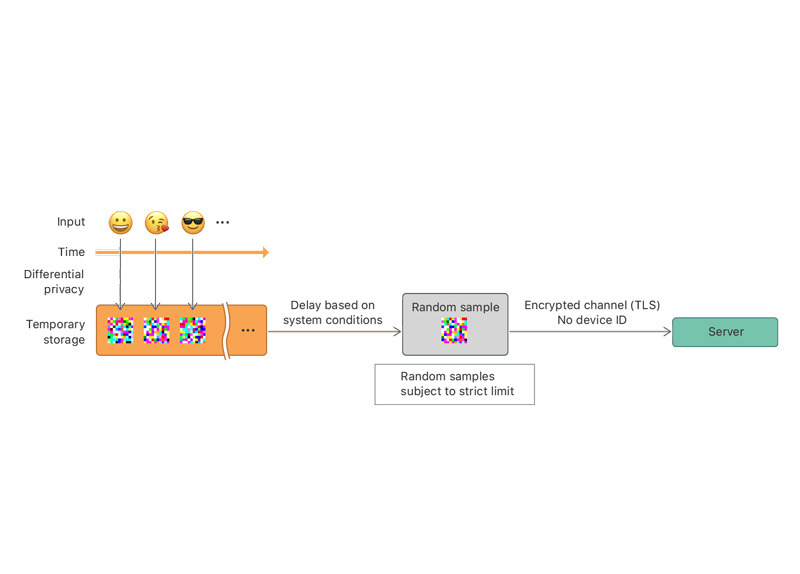
Apple makes use of "local" differential privacy, instead of central, the paper explains. This means that "noise" is generated on a person's device before data is uploaded, rather than afterward, ensuring that fully accurate information never crosses the company's servers.
"When many people submit data, the noise that has been added averages out and meaningful information emerges," according to Apple.
The company also touts the technology technology's opt-in nature, and other safeguards such as the automatically deletion of IP addresses and links between records once information is uploaded.
"At this point, we cannot distinguish, for example, if an emoji record and a Safari web domain record came from the same user," the paper continues. "The records are processed to compute statistics. These aggregate statistics are then shared internally with the relevant teams at Apple."
Some use cases of differential privacy are said to including discovering popular emoji, identifying resource-intensive websites, an improving keyboard autocorrection by learning abbreviations, slang, trending words, and borrowed foreign words.
The technology has sometimes proven controversial, particularly since a study recently claimed that Apple's approach still collects too much specific data. Apple challenged its methodology and conclusions.