
A new research paper shows that Apple has practical solutions to technical AI issues that other firms appear to be ignoring, specifically how to use massive large language modules on lower-memory devices like iPhone.
Despite claims that Apple is behind the industry on generative AI, the company has twice now revealed that it is continuing to do its longer term planning rather than racing to release a ChatGPT clone. The first sign was a research paper which proposed an AI system called HUGS, which generates digital avatars of humans.
Now as spotted by VentureBeat, a second research paper, proposes solutions for deploying enormous large language modules (LLMs) on devices with limited RAM, such as iPhones.
The new paper is called "LLM in a flash: Efficient Large Language Model Inference with Limited Memory." Apple says that it "tackles the challenge of efficiently running LLMs that exceed the available DRAM capacity by storing the model parameters on flash memory but bringing them on demand to DRAM."
So the whole LLM still needs to be stored on-device, but working with it in RAM can be done through working with flash memory as a kind of virtual memory, not dissimilar to how it's done on macOS for memory intensive tasking.
"Within this flash memory-informed framework, we introduce two principal techniques," says the research paper. "First, 'windowing' strategically reduces data transfer by reusing previously activated neurons... and second, 'row-column bundling,' tailored to the sequential data access strengths of flash memory, increases the size of data chunks read from flash memory."
What this ultimately means is that LLMs of practically any size can still be deployed on devices with limited memory or storage. It means that Apple can leverage AI features across more devices, and therefore in more ways.
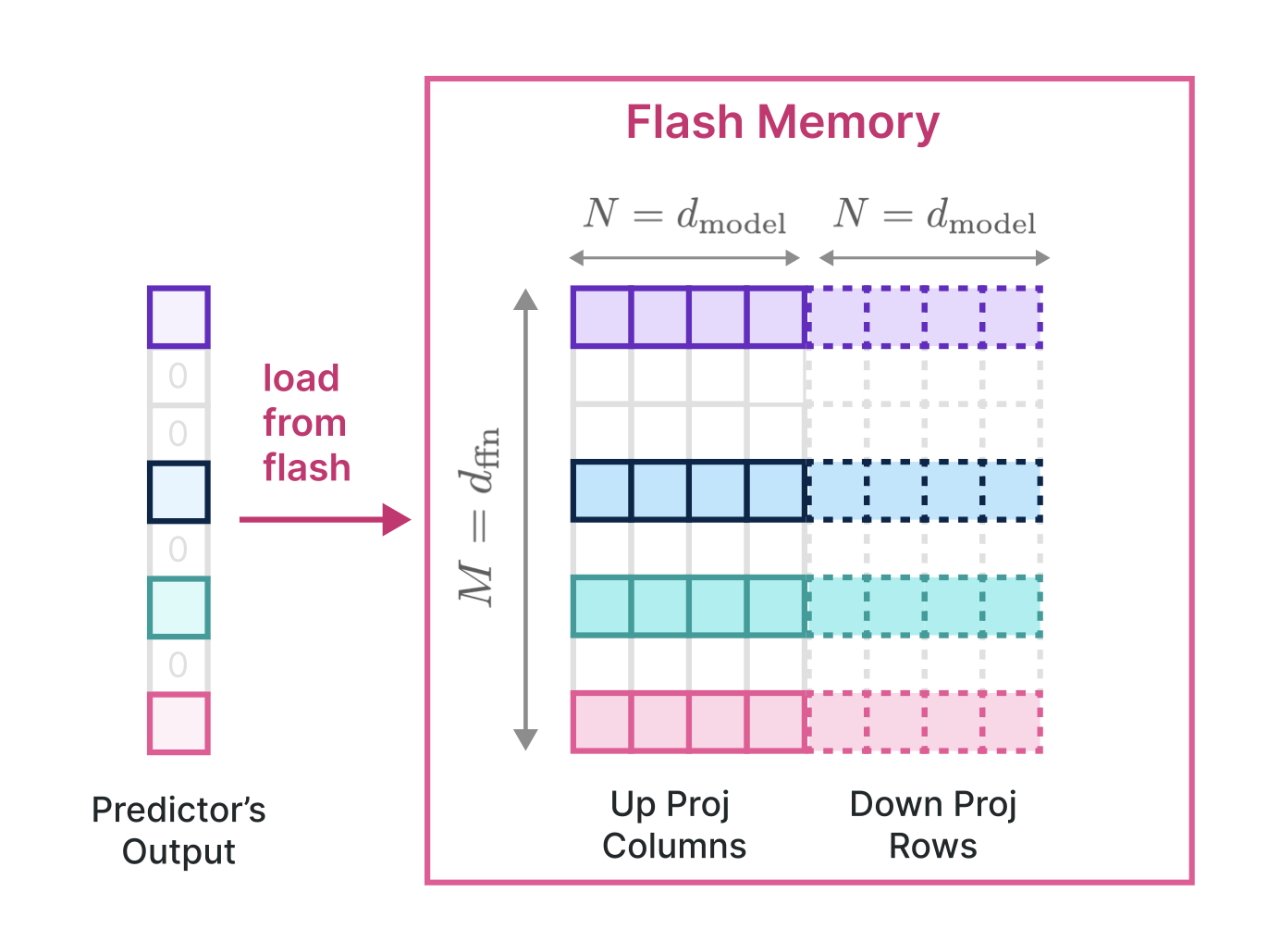
Detail from the research paper showing faster reading of LLMs from flash memory
"The practical outcomes of our research are noteworthy," claims the research paper. "We have demonstrated the ability to run LLMs up to twice the size of available DRAM, achieving an acceleration in inference speed by 4-5x compared to traditional loading methods in CPU, and 20-25x in GPU."
"This breakthrough is particularly crucial for deploying advanced LLMs in resource-limited environments," it continues, "thereby expanding their applicability and accessibility."
Apple has made this research public, as it did with the HUGS paper. So instead of being behind, it is actually working to improve AI capabilities for the whole industry.
This fits in with analysts who, given the user base that Apple does, believe the firm will benefit the most as AI goes further mainstream.







