Apple looking to add character to text-to-speech voices
 Mikey Campbell
Mikey CampbellSource: USPTO
Last updated
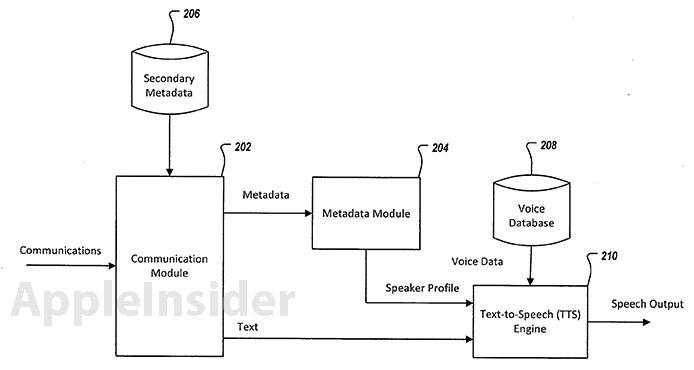
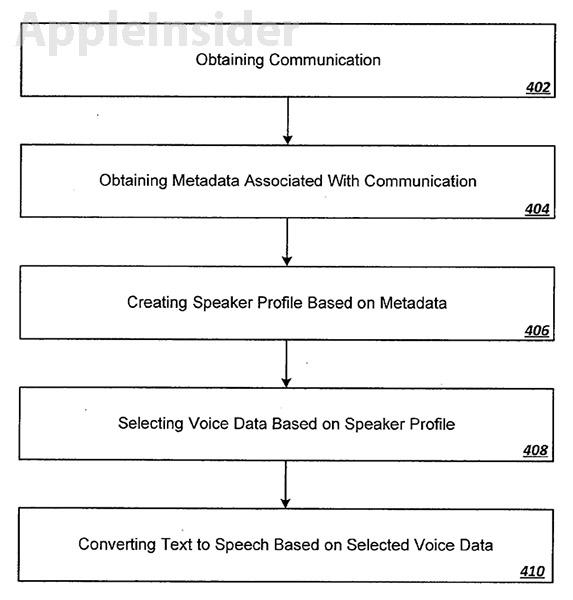
An Apple patent application discovered on Thursday outlines an invention that uses metadata from emails, texts and other communications to determine how a synthesized voice sounds in a text-to-speech (TTS) system.
The filing, titled "Voice assignment for text-to-speech output," looks to create "speaker profiles" which can change the voice characteristics of TTS output to match parsed-out metadata like age, sex, dialect and other variables.
As noted by the application, many systems exist today to aid the visually impaired, including the system on Apple's iPhone, however most TTS engines "generate synthesized speech having voice characteristics of either a male speaker or a female speaker. Regardless of the gender of the speaker, the same voice is used for all text-to-speech conversion regardless of the source of the text being converted." Apple's invention proposes a different solution.
Instead of hearing the same voice for every message, the invention obtains metadata "directly from the communication or from a secondary source identified by the directly obtained metadata" to create the most suitable speaker profile.
According to the patent filing, "Providing a speech output that is associated with a speaker profile allows speaker recognition while providing a more enjoyable and entertaining experience for the listener."
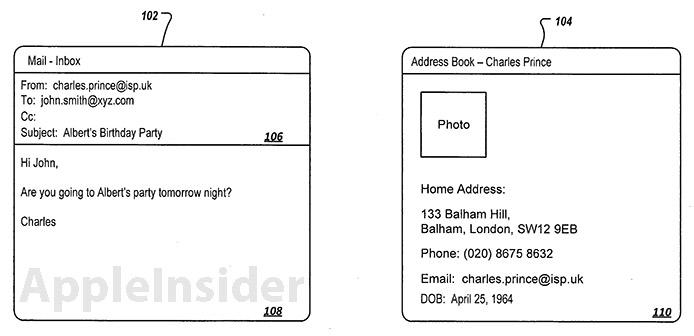
An example is provided in which a user receives a message from "Charles Prince," who has an email address of [email protected], regarding a party for "Albert." In this case, the system could use the ".uk" address as primary metadata. Secondary metadata can be gathered if a contact card is attached to the message, or if Charles Prince's information is already in the user's address book.
Metadata samples.
The data from the text and the corresponding metadata are then fed into a TTS engine, which assigns a speaker profile to convert the text into speech.
After converting each word and phonetic transcription in the text to distinct sounds that comprise a given language, the TTS engine then divides and marks rhythmic sounds like phrases, clauses and sentences.
In some implementations, speech can be created by piecing together pre-recorded voice fragments, including sounds, entire words or even sentences, that are stored on a mobile device or in an off-site database.
In other implementations, the TTS engine can include a synthesizer that "incorporates a model of the human vocal tract or other human voice characteristics to create a synthetic speech output according to the speaker profile."
One of the most interesting iterations notes that "a speaker's voice can be recorded and analyzed to generate voice data."
From the patent filing's description:
For example, the speaker's voice can be recorded by a recording application running on the device or during a telephone call (with permission). The voice characteristics of the speaker can be obtained using known voice recognition techniques. In this implementation, a speaker profile may not be necessary as the speaker's name can be directly associated with voice data stored in voice database.
As for output, the system may pick the ".uk" email address to use as primary metadata, taking contact card information like a birthday to determine sex and age, to subsequently output a speaker profile matching an older male with a British accent. Charles Prince's physical address, phone number, or picture can also be used to determine a speaker profile. The more metadata available, the more refined the output.
Flowchart of TTS system.
It is unclear if Apple plans to deploy such a system, however the company currently has a similar, albeit less advanced, system in place with Siri. While the feature is limited to certain regions, Siri has an option to choose dialects like "English (United States)" or "English (United Kingdom)" to recognize incoming voice commands, as well as provide responses in the selected accent.











 Amber Neely
Amber Neely
 Thomas Sibilly
Thomas Sibilly
 AppleInsider Staff
AppleInsider Staff
 William Gallagher
William Gallagher
 Malcolm Owen
Malcolm Owen
 Christine McKee
Christine McKee










11 Comments
"Hello, sweetheart. I'm so excited by your picture, please write me asap on sexygirl.apple.xxx" ?
Very clever invention! That's a patent I'd love to see working! Adapting voice synthesis from metadata could happen in a first moment, then, after people get used to the tech, voice recording for synthesis could be used. The phone would need to be extremely secure though, I wouldn't want speech patterns for all my contacts get lost in the wild.
[quote name="ClemyNX" url="/t/153509/apple-invention-gives-character-to-text-to-speech-voices#post_2214099"]Very clever invention! That's a patent I'd love to see working! Adapting voice synthesis from metadata could happen in a first moment, then, after people get used to the tech, voice recording for synthesis could be used. The phone would need to be extremely secure though, I wouldn't want speech patterns for all my contacts get lost in the wild.[/quote] This is great and all but it seems very "sci-fi". I'd expect to see many other changes in how text-to-speech works long before this patent gets implemented. For starters, I hate that artists in my Music are spoken incorrectly when the name is well know. This is something that the system should have a digital phonetic spelling of for all artists so that it can be as accurate as possible. Next, I'd like for the system to allow me to record the name of people in my contacts. Not to have my recording is played back to me when Siri reads it off but so that the pattern I use can processed and used to get a playback from the system. For instance, the name Jim is being pronounced as |gim| by Siri. But even names it does get right for the masses might be unique for different dialects or other languages or cultures and it would be nice if Siri tried to know the proper one once being corrected. This is much like the first one expect it's more individual and therefore would be harder to implement. Finally, I'd like for Apple to get with linguists to create a paragraph that details all [URL=http://en.wikipedia.org/wiki/Phoneme]phonemes[/URL] of a language so that when you first sign up for Siri it will have you speak each sentence and will record every part of your voice which it will then process and store with your on-line profile so that it will better understand your accent, your dialect, and/or any speech aberrations you may have.
Speech to text?
It would be wonderful to have "speaker profiles" for everyone I know, so I can send "voice" messages from them to others, destroying their relationships and lives. That's going to be awesome.