"Podcasts of classroom lectures and other presentations typically require manual editing to switch the focus between the video feed of [an] instructor and the slides (or other contents) being presented," Bertrand Serlet, Senior Vice President of Software Engineering at Apple, wrote in the 15-page filing. "In a school or enterprise where many presentations take place daily, editing podcasts require a dedicated person, which can be prohibitive. "
To solve this problem, Serlet proposes has proposed an automated content capture and processing system where a live camera feed of a presenter can be automatically merged with a Keynote or PowerPoint presentation to form an entertaining and dynamic podcast that lets the viewer watch the presenter's slides as well as the presenter.
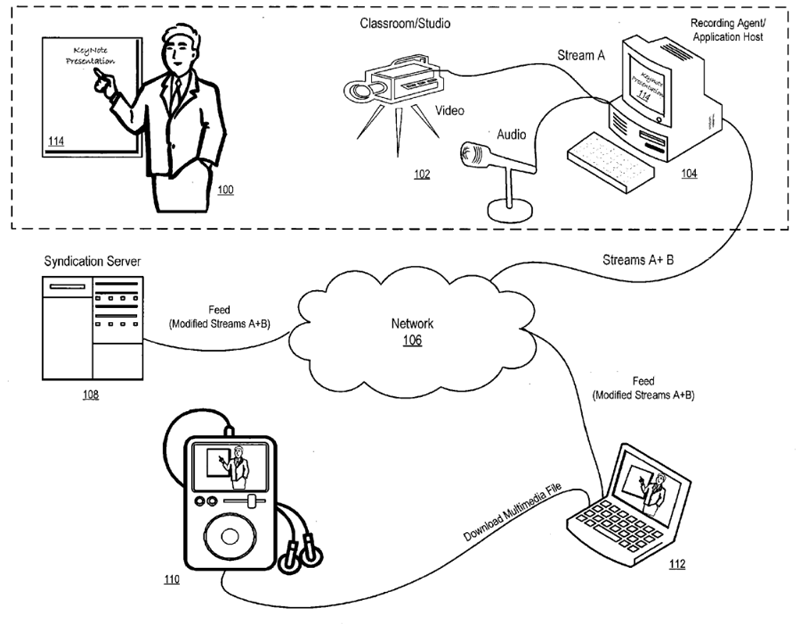
In one example outlined in the filing, the content capture system provides a video stream (Stream A) and an Keynote presentation stream (Stream B) to a recording agent such as a Mac running specialized Podcast creation software. The recording agent then blends the two feeds together based on certain cues and sends the combined feed to a syndication server that would then distribute the video wirelessly as a Podcast to any number of authorized Macs, iPods or iPhones.
Serlet also explained that syndication server could include an automated content creation application that applies one or more operations on the Streams A and/or B to create new content, such as transitions, effects, titles, graphics, audio, narration, avatars, animations, and so forth.
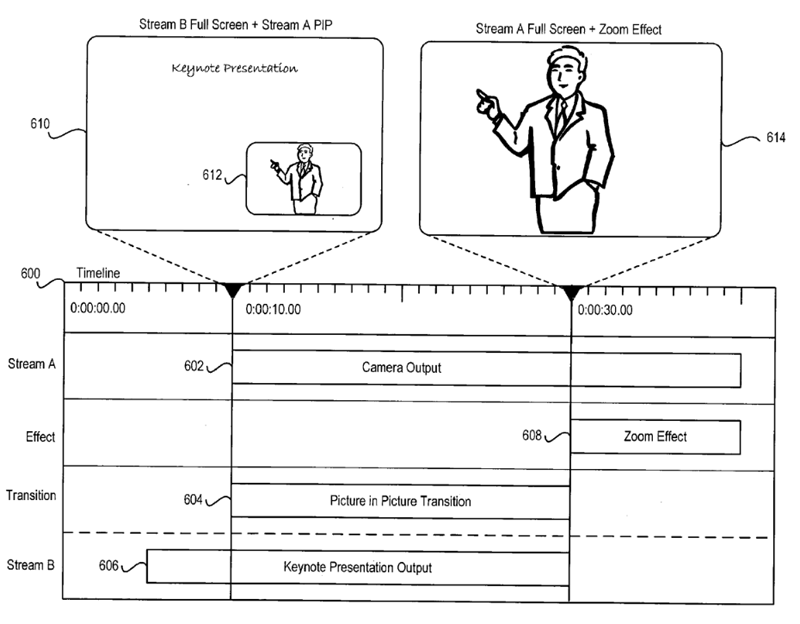
"For example, a content stream (e.g., Stream B) output by the application can be shown as background (e.g., full screen mode) with a small picture in picture (PIP) window overlying the background for showing the video camera output (e.g., Stream A)," he wrote. "If a slide in Stream B does not change (e.g., the "trigger event") for a predetermined interval of time (e.g., 15 seconds), then Stream A can be operated on (e.g., scaled to full screen on the display). A virtual zoom (e.g., Ken Burns effect) or other effect can be applied to Stream A for a close-up of the instructor or other object (e.g., an audience member) in the environment (e.g., a classroom, lecture hall, studio)."
The Apple executive also explained that trigger events can be captured from the actual presentation environment using, for example, the capture system, including patterns of activity of the instructor giving a presentation and/or of the reaction of an audience watching the presentation.
"The instructor could make certain gestures, or movements (e.g., captured by the video camera), speak certain words, commands or phrases (e.g., captured by a microphone as an audio snippet) or take long pauses before speaking, all of which can generate events in Stream A that can be used to trigger operations," he wrote.
"In one exemplary scenario, the video of the instructor could be shown in full screen as a default. But if the capture system detects that the instructor has turned his back to the audience to read a slide of the presentation, such action can be detected in the video stream and used to apply one or more operations on Stream A or Stream B, including zooming Stream B so that the slide being read by the instructor is presented to the viewer in full screen."
Throughout the filing, Serlet outlined examples of several other potential trigger events, such as the movement of a presentation pointer (e.g., a laser pointer) which could then be captured and detected as an event by an "event detector." For instance, the direction of the laser pointer to a slide can indicate that the instructor is talking about a particular area of the slide. Therefore, in one implementation, an operation can be to show the slide to the viewer.
"The movement of a laser pointer can be detected in the video stream using AVSR software or other known pattern matching algorithms that can isolate the laser's red dot on a pixel device and track its motion (e.g., centroiding)," he added. "If a red dot is detected, then slides can be switched or other operations performed on the video or application streams. Alternatively, a laser pointer can emit a signal (e.g., radio frequency, infrared) when activated that can be received by a suitable receiver (e.g., a wireless transceiver) in the capture system and used to initiate one or more operations.
In some other implementations, a detection of a change of state in a stream is used to determine what is captured from the stream and presented in the final media file or podcast. For instance, the instructors transition to a new slide can cause a switch back from a camera feed of the instructor to a slide. When a new slide is presented by the instructor, the application stream containing the slide would be shown first as a default configuration, and then switched to the video stream showing the instructor, respectively, after a first predetermined period of time has expired. In other implementations, after a second predetermined interval of time has expired, the streams can be switched back to the default configuration.
Taking his next-generation podcast concept a step further, Serlet went on to say that the capture system could conceivably include a video camera that can follow the instructor as he moves about the environment. The cameras could be moved by human operator or automatically using known location detection technology. The camera location information could then be used to trigger an operation on a stream and/or determine what is captured and presented in the final media file or podcast.
It should be noted that Serlet's concept one of at least three Podcast enhancements proposed by Apple employees in recent patent filings, none of which have come to fruition as of yet. Others include personalized on-demand podcasts and Podmaps.