Apple's researchers continue to focus on multimodal LLMs, with studies exploring their use for image generation, understanding, and multi-turn web searches with cropped images.
With iOS 18, Apple made it possible to generate images on an iPhone through local AI models. Image Playground lets you create cartoon-like photos of just about anything, all without a Wi-Fi connection.
Now, the company is continuing its image-related endeavors through research that explores how multi-modal LLMs use, generate, and understand images.
Among other research papers made available in January 2026, Apple released a paper dubbed "DeepMMSearch-R1: Empowering Multimodal LLMs in Multimodal Web Search." The study, which can be found on the Apple Machine Learning blog, explores the use of images and image cropping by LLMs for web searches.
Also related to AI and its use of images, another Apple research paper details a multimodal LLM that can both generate images from text and understand the contents of an image.
Here's what the research papers themselves revealed.
DeepMMSearch-R1 — How image-cropping helps multi-modal LLMS run web searches
Before describing the DeepMMSearch-R1 LLM, Apple's researchers outline the shortcomings of existing search-equipped multimodal LLMs and explain how they can provide incorrect information, or no information at all.
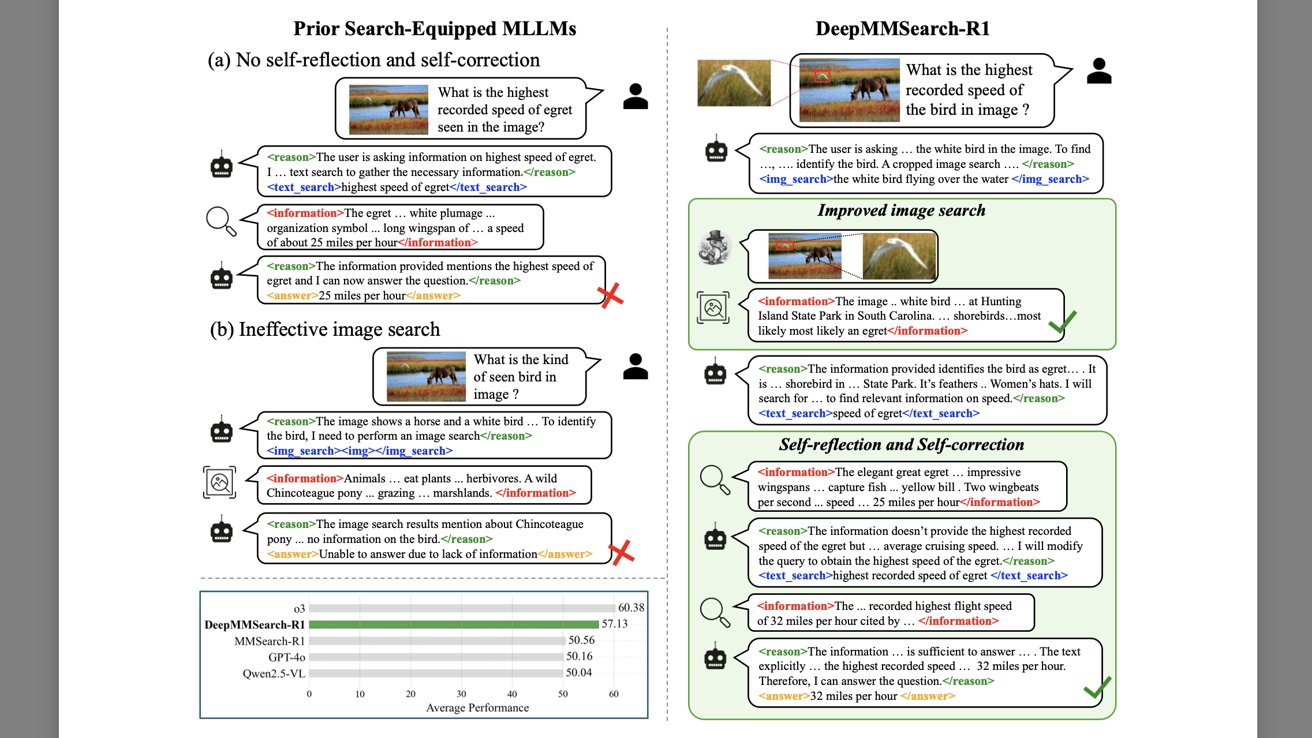
Apple's AI model can crop images, and use them for image searches and text-based web searches.
This is illustrated through two examples revolving around a type of bird known as an egret.
When asked about "the highest speed of an egret," some LLMs may provide an incorrect answer because they ended up finding the average speed of the bird, instead of the highest recorded speed. The LLM finds a text that contains the words "speed" and "egret" and presents an incorrect answer.
In the second example, an LLM is presented with an image of a horse, featuring a bird in the top left corner. When asked about the type of bird in the photo, the LLM conducts an image search and gets no results about the bird. Consequently, the user doesn't get an answer.
Apple's approach involves a multimodal LLM that can crop an image as needed, and correct or double-check its answers before sending them to the end user.
Going back to the example with the bird, DeepMMSearch-R1 is provided with the same image featuring a horse and an egret. It's asked about the highest recorded speed of the bird in the photo.
The LLM first crops the image so that only the bird remains, and it runs an image search. Once it has identified the bird as an egret, it searches the web and makes sure that its result contains the highest recorded speed rather than anything else.
In essence, DeepMMSearch-R1 consists of:
- a text search tool — lets the model search webpages for up-to-date factual knowledge
- a grounding tool — allows the model to crop an image when necessary for a web search
- an image search tool — gathers web content, including titles and descriptions based on a complete or cropped image
The model itself was trained using a two-stage process "consisting of an initial supervised finetuning (SFT) phase followed by online reinforcement learning (RL)." SFT stopped the model from performing unnecessary cropping, while RL led to more efficient tool use.

Apple's researchers were able to fine-tune the multimodal LLM so that it only uses the cropping tool when necessary.
When testing the model, the iPhone maker's researchers found that DeepMMSearch-R1 "surpasses both RAG workflows and prompt-based search agent baselines by a significant margin."
The people behind the model believe that "DeepMMSearch-R1 represents a compelling step forward in real-world, multimodal information-seeking AI, with promising applications in web agents, education, and digital assistance."
While DeepMMSearch-R1 revolves around web searches, another Apple study explores how multimodal LLMs process and create images, and explains whether there's room for improvement.
Manzano — The multimodal LLM can generate and understand images
The research paper titled "MANZANO: A Simple and Scalable Unified Multimodal Model with a Hybrid Vision Tokenizer" outlines a multi-modal LLM that is capable of understanding and generating images without prioritizing either of the two features.
The Manzano LLM is capable of understanding, editing, and generating images, without trade-offs.
Manzano, a multimodal large language model, is one that "unifies understanding and generation tasks using the auto-regressive (AR) approach."
While the researchers recognized the prominence and capabilities of existing models, such as OpenAI's GPT-4o, they also point out that most unified AI models prioritize either image generation or image understanding, which inevitably results in drawbacks or trade-offs.
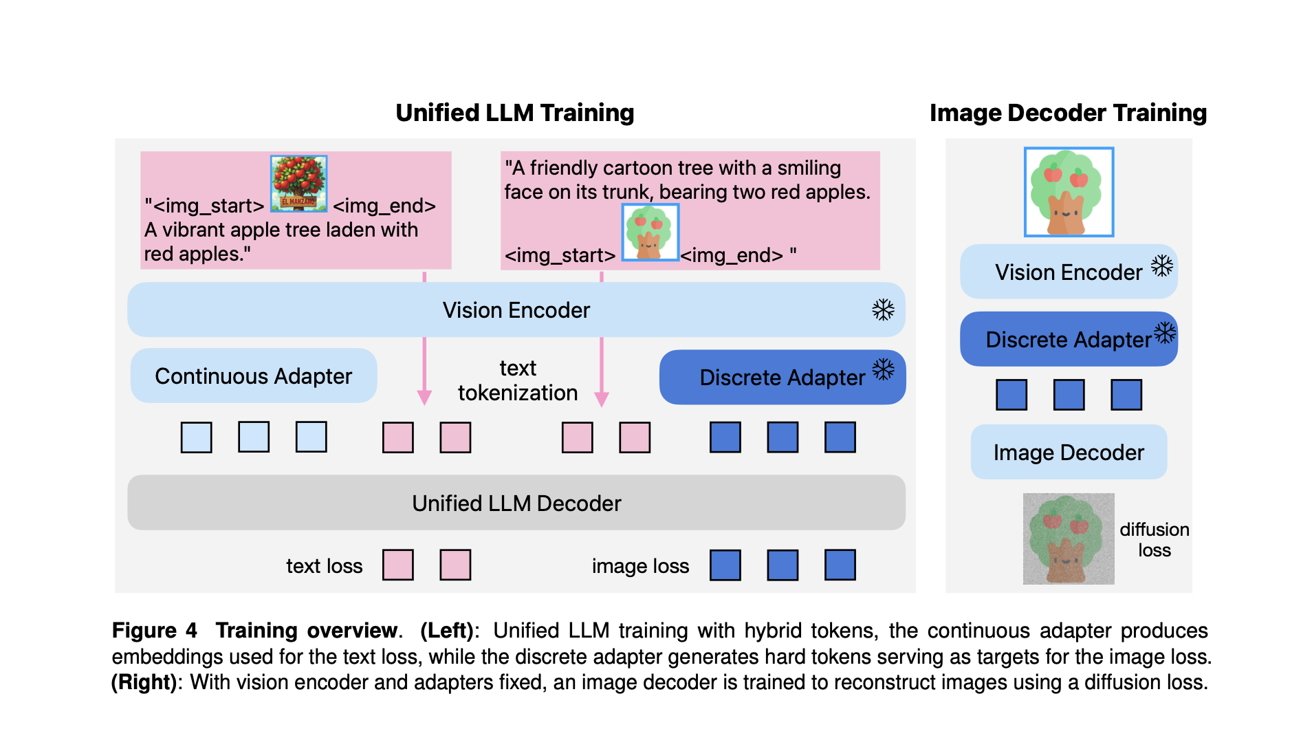
Apple's researchers explain how they opted for an approach somewhat different from GPT-4o. "Instead of employing separate tokenizers for understanding and generation, we introduce a unified semantic tokenizer to produce both continuous features for understanding tasks and quantized features for generation tasks."
The research paper emphasizes that the researchers' strategy "substantially mitigates the task conflict that commonly arises."
The model itself consists of three core elements:
- A unified shared visual encoder/tokenizer with a continuous adapter for understanding tasks and a discrete adapter for generation
- An LLM decoder that accepts text tokens and/or continuous image embeddings and auto-regressively predicts the next discrete image or text tokens from a joint vocabulary
- An image decoder that renders image pixels from predicted image tokens
The first two components are necessary for both image understanding and generation. The purpose of the image decoder, meanwhile, is to actually create an image using Gaussian noise.
This structure allowed Apple's researchers to train Manzano "with a joint recipe to learn image understanding and generation simultaneously." The multimodal LLM was trained on text-only, interleaved image-text, image-to-text, and text-to-image data.

Manzano performs better with a larger LLM decoder.
The research paper says that Manzano achieves "state-of-the-art performance on both understanding and generation tasks." Apple's researchers tested multiple variants of Manzano, with LLM decoder sizes of 300M, 1B, 3B, and 30B. Manzano typically performed better when the LLM decoder size was larger.
Still, the research paper explains that "the unified LLM trained with our hybrid tokenizer performs on par with the dedicated, single-task models on nearly all tasks, even at a compact size like 300M." Regarding the 3B and 30B variants of Manzano, Apple's researchers say they "achieve superior or competitive performance compared to other SOTA unified multimodal LLMs."
The multimodal LLM can also process "counterintuitive, physics-defying prompts (e.g., 'The bird is flying below the elephant') comparably to GPT-4o and Nano Banana." Other examples included a corgi holding up a sign saying it's not a corgi.

Manzano can process counterintuitive, physics-defying prompts.
Additionally, Manzano supports "versatile editing capabilities, including instruction-guided editing, style transfer, inpainting, outpainting, and depth estimation." In essence, it's capable of altering images at the user's request, even when it has to fill in the "missing" portions of an image.
Apple's researchers ultimately concluded that a unified multimodal LLM, capable of both image generation and understanding, doesn't need to prioritize one capability over the other for good results.
In terms of practical applications, we could see new image-related tools make their way to Siri, at some point. Apple's expected to roll out an upgraded version of Siri, powered by Google Gemini, with the release of iOS 26.4 in the spring of 2026.