
Apple Intelligence researchers are proposing a new approach to text-to-speech that would make Siri quicker to respond. That might, though, also make conversations flow more naturally.
Apple may have lost the odd AI researcher, but it continues to publish significant papers on the topic. Previously it has published about limiting AI from taking actions a user didn't approve, and examining how to prevent hallucinations.
Now in a study called "Principled Coarse-Grained Acceptance for Speculative Decoding in Speech," researchers from Apple and Tel Aviv University, have focused on text-to-speech applications.
In AI, speech is sometimes generated based on tokens, or very short samples of sound. These are phonetic sounds, measured in milliseconds, which are then assembled into sentences.
We've all heard Siri in Apple Maps give the odd peculiar pronunciation of a place or a road name, and that's down to which phonetic sounds were chosen to be used. Maps directions have to be delivered on time if they're to be of any use, so speed of generating the speech is crucial.
It's also important in other circumstances, where a prompt response helps with conversational exchanges.
What Apple's researchers argue in this new paper is that the process of taking text and looking up the best speech token can be done faster than at present. They argue that previous methods which work through every token using autoregression — narrowing down results as the search continues — are not optimal.
Apple says that this working through each token means that processes ignore "acoustic similarity" and also risk "erroneous acceptances."
In this proposal, Apple suggests replacing this exact token-matching system, and instead looking first for what they define as Acoustic Similarity Groups (ASGs). Claiming "two key innovations," Apple says that ASGs contain "perceptually similar sounds," but also that the sounds can belong in multiple, overlapping groups.
Using probabilities, such a text-to-speech system can narrow down the search to a smaller set of tokens. Within multiple ASGs, the process can use autoregression to further eliminate the wrong sounds within each group.
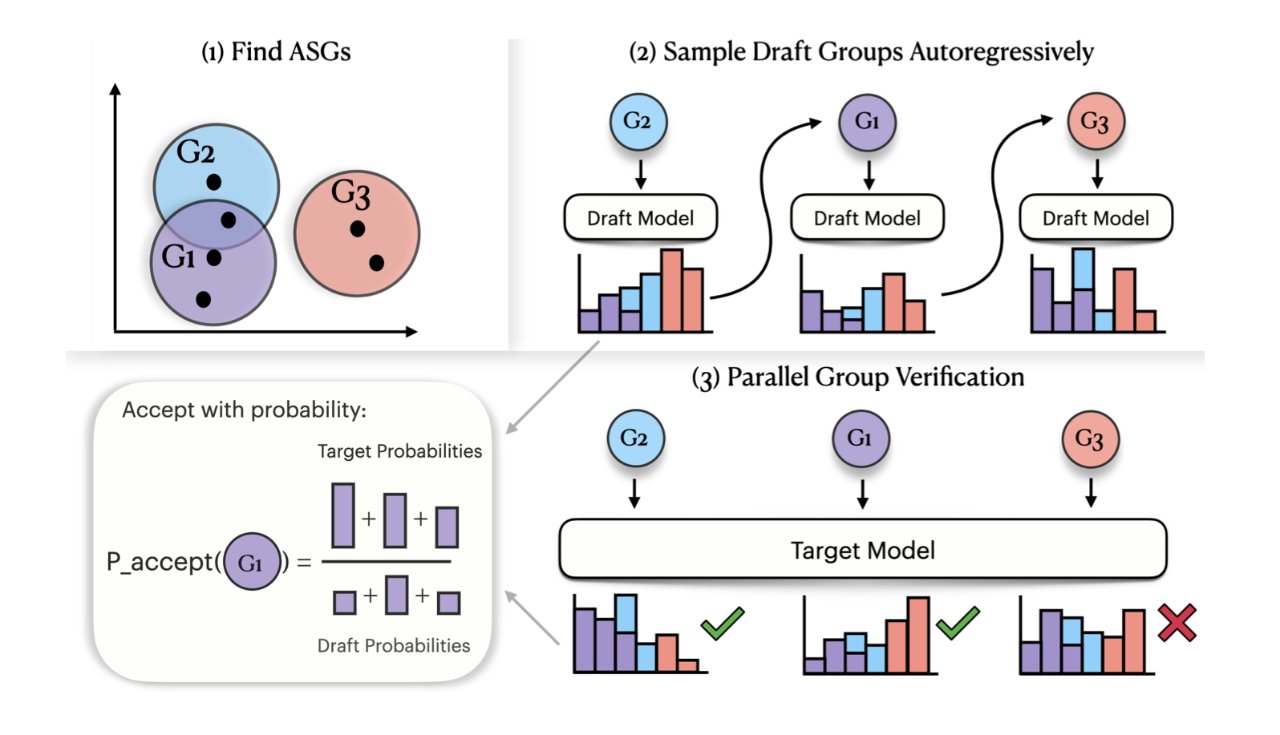
Detail from the research paper outlining how grouping sounds phonetically can make them quicker to find — image credit: Apple
Then it can use probabilities to select from the groups, what should be the most accurate speech token to use in its spoken response. Apple argues that its full process is faster "while better preserving generation quality" than previous models.
What this should mean is that conversations with systems such as Siri would flow more quickly. The speed difference is unlikely to be enormous, but humans are used to human speech, and delays are noticeable.
The paper does not focus on improving how natural a text to speech system is, but speed would help. Separately, Apple researchers have long been looking at ways to improve how Siri's spoken responses could be tailored to suit a user's preferences or environment.






